简介
最近闲来无事逛github时发现bistoury,Bistoury是去哪儿网的java应用生产问题诊断工具,提供了一站式的问题诊断方案,可以在生产环境中实现非入侵式系统信息查看,包括堆栈信息,机器情况,在线调试,应用线程信息等.
####简介
在线上环境中有时会遇到cpu等资源占用过多的资源我们可以使用top命令和jstack命令对问题进行排查
下面代码开启两个线程循环打印
1 | public class Test { |
开启jar应用
1 | nohup java -jar test.jar >/dev/null 2>&1 & |
我们可以从命令中看到pid 19384占用了大量资源
1 | top |
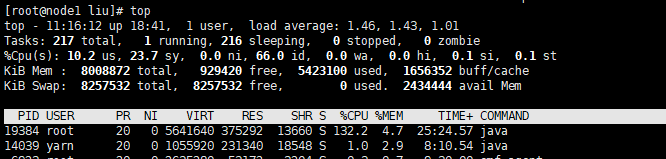
从上一步我们得到进程pid,现在我们使用top命令查看进程pid下的线程
1 | top -Hp 19384 |
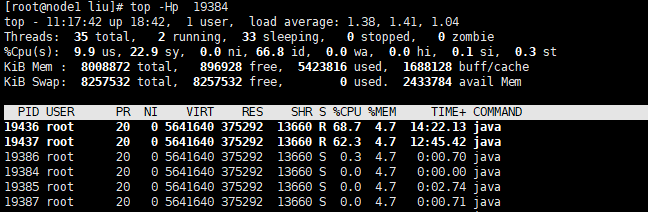
我们可以看到19436 和19437这两个线程占用了大量资源
根据进程pid进行查询
1 | jstack -l 19437 |
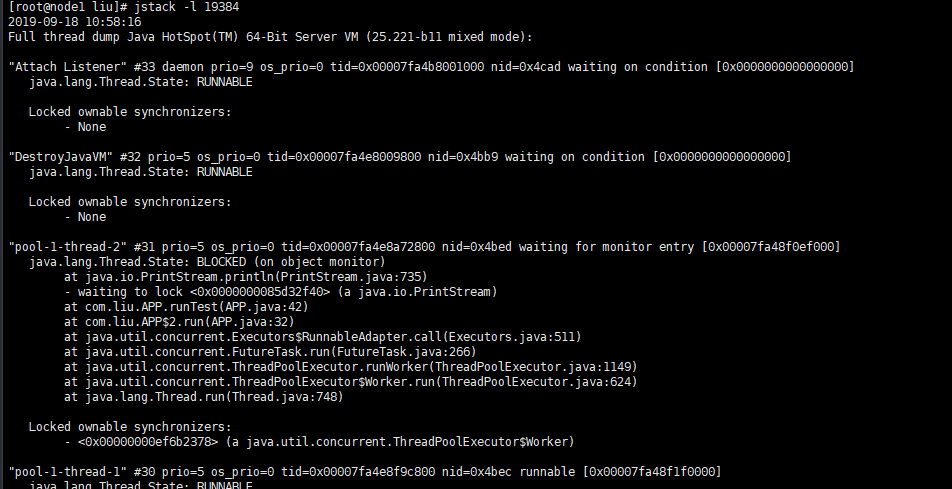
我们由上面的top线程查询到19436和19437这两个线程占用了大量资源
将其转化成16进制分别为4bec和4bed
根据16进制的pid查询对应的nid,如图我们找到了pool-1-thread-2 这个线程名对应的nid为4bed,这个线程就是我们之前开启的一个线程,我们可以查看之中的堆栈信息发现其在runTest方法中持续执行,并且持续在执行io流(打印)
除了上述的分析,大多数情况下会基于thead dump分析当前各个线程的运行情况,如是否存在死锁、是否存在一个线程长时间持有锁不放等等。在dump中,线程一般存在如下几种状态:
在实际调试中这两个线程无法并发执行,始终都是一个线程为RUNNABLE,一个为BLOCKED,但是实际代码并未加锁,根据堆栈打印出的信息线程中是在io流中加了锁
1 | locked <0x0000000085c3d2e0> (a java.io.OutputStreamWriter) |
于是查看System.out.println(“ “)的源代码,可以看出源码中打印代码时加了锁的,所以导致两个线程无法并发
1 | public void println(String x) { |
C2 Compiler 线程 是JVM在server模式下字节码编译器,JVM启动的时候所有代码都处于解释执行模式,当某些代码被执行到一定阈值次数,这些代码(称为热点代码)就会被 C2 Compiler编译成机器码,编译成机器码后执行效率会得到大幅提升。流量进来后,大部分代码成为热点代码,这个过程中C2 Compiler需要频繁占用CPU来运行,当大部分热点代码被编译成机器代码后,C2 Compiler就不再长期占用CPU了,这个过程也可以看作抖动。解决C2 CompilerThread1抖动方法,可以使用Jmeter等压测工具模拟线上访问流量,让C2 Compiler预先将热点代码编译成机器码, 减少对正式环境流量的影响。
下载elasticsearch 6.8.2版本
tar -xvf 文件路径
$ ./bin/elasticsearch &
max file descriptors [4096] for elasticsearch process is too low, increase to at least [65536] 问题
1 | #切换到root用户修改 |
root无法启动问题
1 | root用户无法启动elasticsearch,切换至其他用户并执行 |
非本机无法访问rest服务
1 | 修改 config/elasticsearch.yml 修改以下标签为值 |
前面已经简介过领域驱动的基本概念,前文介绍的COLA框架在大型项目或者微服务架构中目测有较好的实践,但是对于一个中小项目或者小公司来说管理大量依赖包模块简直就是噩梦,或者就是项目达不到那种规模,采用分包模式也是一种浪费,但是采用领域驱动设计在本人实践过程中确实大大提升了代码质量,最主要的改善就是使开发人员不再以数据库驱动开发,而是真正的开始从业务和领域入手,这样开发出的代码往往能更好的实现面向对象,将代码划分出边界,使代码的可读性更强,代码更加健壮。本文结合现实中使用领域驱动设计时遇到的问题进行了总结,如果错误还需海涵。
本文代码存放在 https://github.com/liushprofessor/ddd-demo 中
关于领域驱动设计的基础概念可查看本人个人博客中关于领域驱动部分,另外这纯属个人在实践中的总结,如有错误欢迎拍砖指导。
本项目主要有3个大包分别包含3次不同的实践,实践的具体内容如全文所述
user 为第一次实践包含各种模型设计和简介
user2 正对user包下存在的一些问题做了一些优化设计,请查看全文来看具体说明
project 为了针对实际项目中出现的大聚合来做的一些设计,这个包下只建立了模型设计,其余部分如果感兴趣可以自己补充(其实就是本人偷懒)
使用方法如果你使用的是mysql数据库那么修改application.properties中的数据源即可,liquibase会自动将所需要的表建立完毕
可自行到github上查看md简介
https://github.com/alibaba/COLA
COAL提供了一个很方便的maven生成模板,按照项目说明我们生成一个web项目,打开目录我们发现如下几个子模块
接触领域驱动设计已经有一年多的时间了,其更关注的是解决复杂的软件设计。这期间也拿一些小项目尝试实践过,也看过一些领域驱动的框架如Halo,Cola,在实践过程中发现如果小项目如果采用简化版的领域驱动设计的理念去实践,代码结构也会有明显的改善,在小项目实践过程中更关注的是边界的划分,和不同功能模块代码的解耦,把核心的领域代码和其它代码区分出来,更好的将代码和现实业务结合起来,更好的执行面向对象,在使用领域驱动设计时能让我们从数据库驱动设计的理念中转换出来,在设计时假设计算机内存是无限大,只考虑领域模型,而不考虑数据库模型,从而使代码更贴近业务,我觉得这是领域驱动设计给我带来的感触。就比如架构,架构的本质无非就是把代码的边界区分好,把代码放在该放的地方Eric Evans提出的领域驱动设计是一个很好的解决这部分问题的方法。
领域驱动设计,领域代表着行业,你的软件是应用在哪个行业实现什么样的功能,比如你编写了一个财务软件,那么财务行业就是你编写软件的领域,Eric Evans强调软件一定是要由领域专家和领域知识去驱动开发的,因为软件最终是要应用到领域当中,如果绕过这部分内容直接开发软件,那么开发的软件往往无法交付或者无法满足功能,在我认为,软件是现实生活中的映射,在开发第一个版本的时候,可以和领域专家或者领域中的从业人员进行交流业务流程(现实往往只能找到产品经理),交流一下在没有软件的情况下,线下业务是如何进行的,然后再根据这些流程去建立领域对象,去驱动整体的软件设计。