简介
mysql的innoDB存储引擎提供了缓冲池innodb_buffer_pool_size来设置缓冲池的大小,其可以缓存索引,行数据,自适应哈希索引,插入缓冲等数据,InnoDB还使用缓冲池来帮助延迟写入,这样就能合并多个写入操作,然后一起顺序地回写。之前与另一个配置query_cache_size混淆,query_cache_size在8.0中已经废除,因为如果查询缓存中使用了很大的内存,缓存失效操作会成为一个严重的问题瓶颈导致系统僵死一会(更新表中的数据会导致该表的缓存失效),因为这个操作是靠一个全局锁保护的,所有需要该操作的查询都要等待这个锁,而且无论是检测是否命中缓存,还是缓存失效检测都需要等待这个全局锁。以下是网上找的对于这两个缓存的定义.
Qcacche缓存的是SQL语句及对应的结果集,缓存在内存,最简单的情况是SQL一直不重复,那Qcache的命令率肯定是0
buffer pool中缓存的是整张表中的数据,缓存在内存,SQL再变只要数据都在内存,那么命中率就是100%。
事务日志
事务修改的数据和索引通常会映射到表空间的随机位置,这导致大量随机I/O,对机械硬盘来说,随机I/O伴随着磁盘大量寻址操作。InnoDB使用日志把随机I/O变成顺序I/O,一旦日志安全写到磁盘,事务就持久化了,即使变更的数据还没写入到数据文件,一旦系统发生崩溃,InnoDB可以重放日志并且恢复已经提交的事务,当然InnoDB最后必须把日志里的变更数据写入到数据文件当中,因为日志有固定大小。可以通过innodb_log_file_size来设置日志文件大小,在8.0中默认是48M,对于高性能工作来说这太小,至少需要几百M,还有一种说法是能存储1-2个小时的时间.
innodb_buffer_pool_size的大小设置
缓冲池一般设置为服务器内存的75%-80%(前提是该服务器只部署mysql,如果还部署其它应用需扣除其它应用使用的内存)
大innodb_log_file_size和innodb_buffer_pool_size导致的问题
数据大小和访问模式也将影响恢复时间。假设有一个1TB的数据和16G的缓冲池,并且日志大小是128M,如果缓冲池里有很多脏页(例如数据写入了日志文件,但是没有写入数据文件),并且这些数据均匀的分布在1TB数据中,系统崩溃后恢复将需要相当长的一段时间,InnoDB必须从头到尾扫描日志,检查数据文件,并且将事务日志中的数据写到数据文件当中。
日志缓冲刷新到持久化系统(innodb_flush_log_at_trx_commit)
当InnoDB变更任何数据时,会写入一条变更记录到内存的日志缓冲区,在缓冲满的时候,或者每一秒中,或者事务提交时—-无论上述三个条件哪个先到,日志缓冲区默认1M,通过innodb_log_buffer_size配置,如果有大事务,将其配置大一些可以帮助减少磁盘I/O,通常不需要设置的很大1M-9M即可。
innodb_flush_log_at_trx_commit有3个值
- 0:把日志缓冲写到日志文件,并且每秒刷新一次
- 1: 将日志缓冲写到日志文件,并且每次事务提交都刷新到持久化系统,这是默认的,并且是最安全的,该设置保证不会丢失任何已经提交的事务,除非磁盘或者系统是伪刷新。
- 2:每次提交时把日志缓冲写到日志文件,但是不刷新,InnoDB每秒刷新一次。0和2的区别是如果mysql挂了,2不会丢失任何事务,因为2会自动刷新缓存到日志文件在事务提交的时候,但是如果整个服务挂了,则还是可能会丢失一部分事务。这个很好理解,如果我提交了事务,数据已经写入了日志文件所以不会丢失,但是缓存区里未提交的事务,且时间还没到1秒,则会丢失这一秒的数据
因此如果设置0或者2另一个以mysql崩溃或者断电会导致最多丢失一秒的数据。
(innodb怎样打开和刷新日志文件和数据文件)innodb_flush_method
这个配置既影响日志文件,也影响数据文件
将innodb_flush_method设置为O_DIRECT以避免双重缓冲.唯一一种情况你不应该使用O_DIRECT是当你操作系统不支持时。但如果你运行的是Linux,使用O_DIRECT来激活直接IO。
不用直接IO,双重缓冲将会发生,因为所有的数据库更改首先会写入到OS缓存然后才同步到硬盘 – 所以InnoDB缓冲池和OS缓存会同时持有一份相同的数据。特别是如果你的缓冲池限制为总内存的50%,那意味着在写密集的环境中你可能会浪费高达50%的内存。如果没有限制为50%,服务器可能由于OS缓存的高压力会使用到swap。
简单地说,设置为innodb_flush_method=O_DIRECT。
以下是InnoDB的缓存和文件的流程图
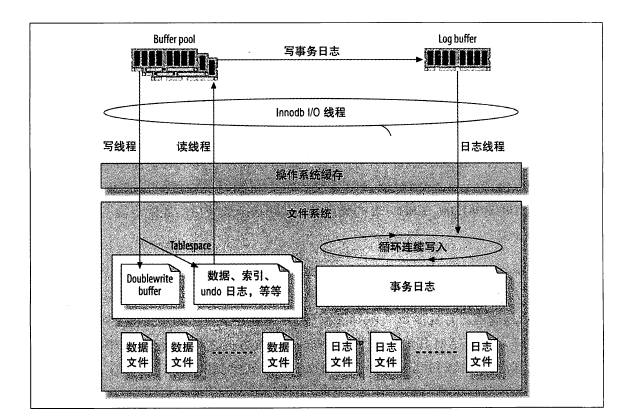
Buffer pool中将变更写入Log Buffer,Log Buffer将数据写入事务日志文件,InnoDB使用一个后台线程智能的刷新这些变更到数据文件,实际上,事务日志把数据文件的随机I/O转换成为几乎顺序的日志文件和数据文件I/O。把刷新操作转移到后台使查询可以更快完成,并且缓和查询高峰时I/O系统的压力,这个也很好理解,数据更新后将数据存放在Buffer pool中为了保证数据不丢失,并且降低I/O损耗采用日志顺序I/O记录这些变更,在系统崩溃时采用日志恢复,并且后台定时将日志文件刷新到数据文件,查询缓存直接查询Buffer pool中的数据即可。
为什么innoDB无法存储大数据量
说白了主要就是innodb_buffer_pool_size缓存不够引起的原因
缓存池可以被认为一条长LRU链表,该链表又分为2个子链表,一个子链表存放old pages(里面存放的是长时间未被访问的数据页),另一个子链接存放new pages(里面存放的是最近被访问的数据页面)。old pages 默认占整个列表大小的37%(这个值对应my.conf 的 innoDB_old_blocks_pct 参数的默认值为37,取值范围是5~95),其余为new pages占用。
如图下图所示。靠近LRU链表头部的数据页表示最近被访问,靠近LRU链表尾部的数据页表示长时间未被访问,而这两个部分交汇处成为midpoint。
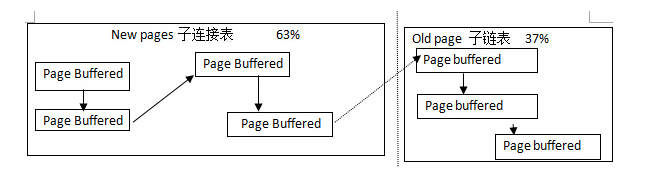
当系统查询数据时当innodb_buffer_pool_size已满时会将排在old pages中的数据挤出缓存,导致innodb_buffer_pool中找不到查询数据,导致磁盘的I/O操作。
另外请参考https://www.cnblogs.com/leefreeman/p/8315844.html
参考资料
高性能Mysql
https://www.centos.bz/2016/11/mysql-performance-tuning-15-config-item/
